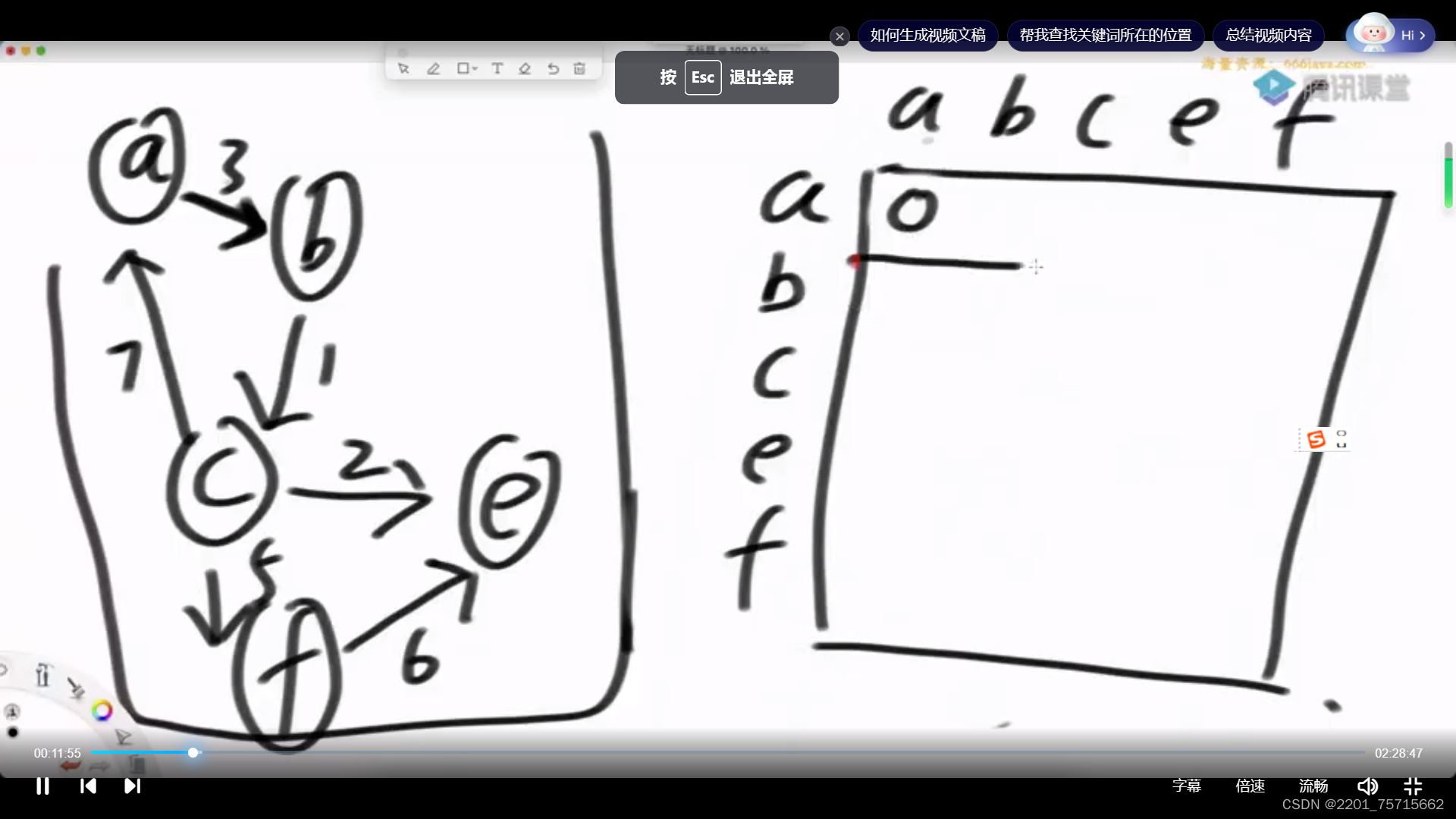
邻接矩阵法
1图的数据结构抽象
#include<vector>
#include<unordered_map>
#include<unordered_set>
using namespace std;
//点结构的描述,由值入度出度后继节点和边构成
class node {
public:
int value;
int in;
int out;
vector<node*> nexts;
vector<edge*> edges;
node(int val):value(val),in(0),out(0){}
};
//边由权重,出发点,终点组成
class edge {
public:
int weight;
node* from;
node* to;
edge(int wei,node *a,node *b):weight(wei),from(a),to(b){}
};
class graph {
public:
unordered_map<int, node*> nodes;//哈希表是为了让一个点的值和节点对应起来
unordered_set<edge*> edges;
graph(){}//此时是一张空图所以什么也不用干
};
// matrix 所有的边
// N*3 的矩阵
// [weight, from节点上面的值,to节点上面的值]
//
// [ 5 , 0 , 7]
// [ 3 , 0, 1]
//
graph creategraph(vector<vector<int>>& matrix)
{
graph g;
for (auto& a : matrix)
{
int weight = a[0];
int from = a[1];
int to = a[2];
//没有的节点就建出来
if (g.nodes.find(from) == g.nodes.end())
{
g.nodes[from] = new node(from);
}
if (g.nodes.find(to) == g.nodes.end())
{
g.nodes[to] = new node(to);
}
node* fromnode = g.nodes[from];
node* tonode = g.nodes[to];
edge* newedge = new edge(weight, fromnode, tonode);
fromnode->nexts.push_back(tonode);
fromnode->out++;
tonode->in++;
fromnode->edges.push_back(newedge);
g.edges.insert(newedge);
}
return g;
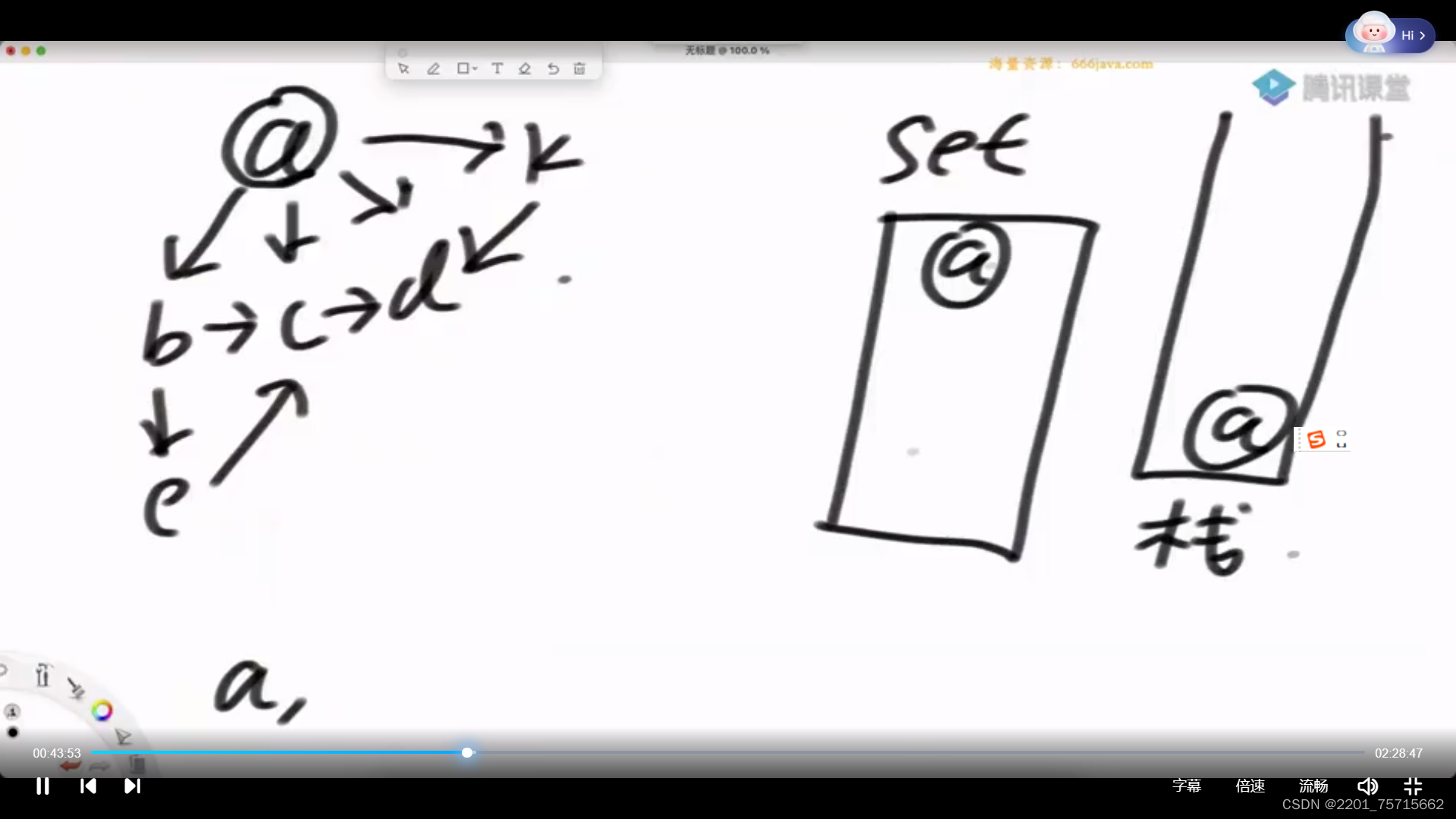
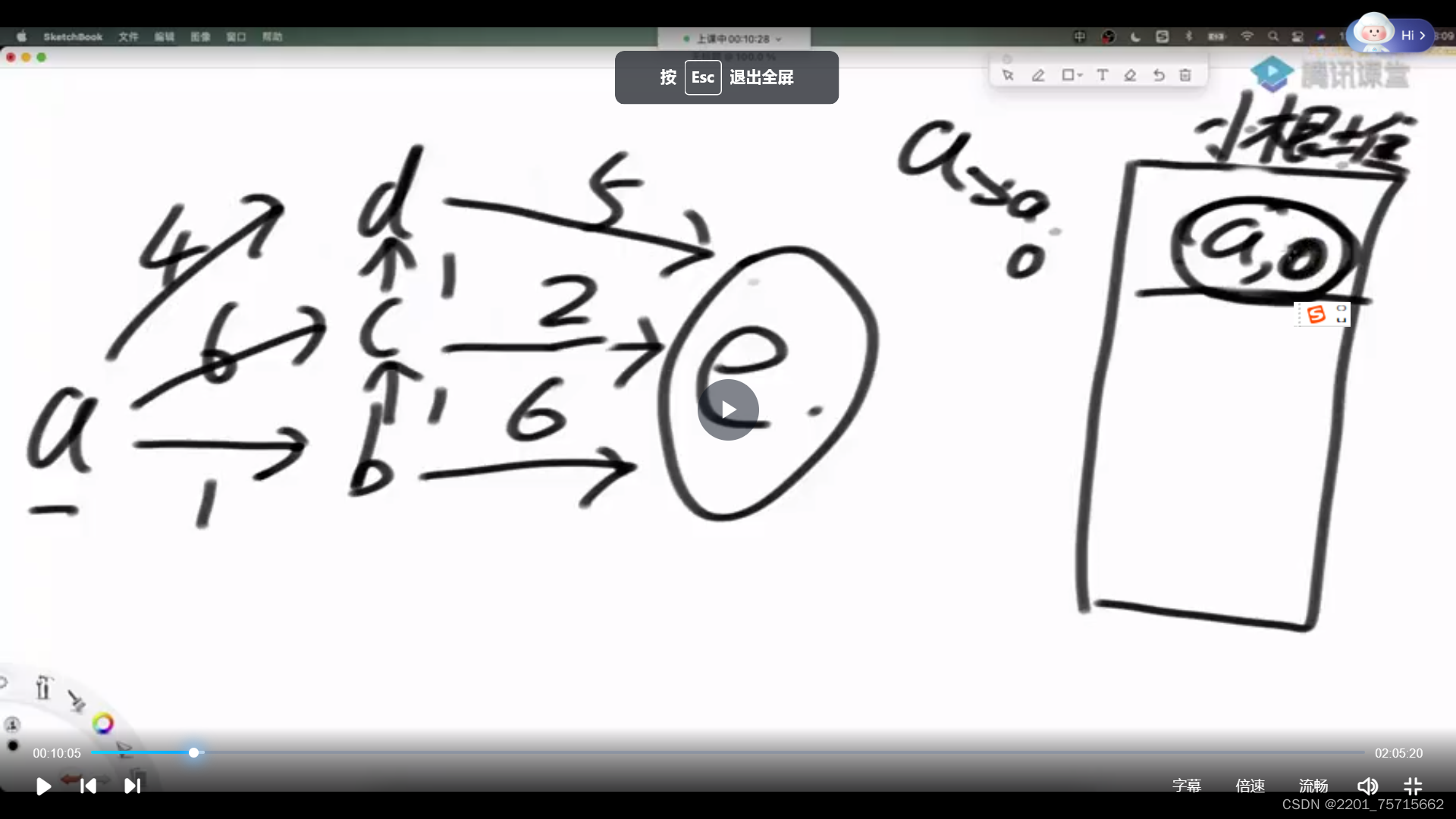
}2图的宽度优先遍历
要用上set集合,不然可能会绕在回路里面
3深度优先遍历
一条路没走完就走到死,然后往上再找有没有其他路可走
栈里面永远放着目前整条路径
#include<vector>
#include<queue>
#include<unordered_set>
#include<iostream>
#include<stack>
using namespace std;
//点结构的描述,由值入度出度后继节点和边构成
class node {
public:
int value;
vector<node*> nexts;
node(int val):value(val){}
};
//实现图的广度优先遍历
void bfs(node* start)
{
if (start == nullptr)
return;
queue<node*> q;
unordered_set<node*> visited;
q.push(start);
visited.insert(start);
while (!q.empty())
{
node* cur = q.front();
q.pop();
//经过的就打印
cout << cur->value << " ";
for (node* next : cur->nexts)
{
if (visited.find(next) != visited.end())
{
q.push(next);
visited.insert(next);
}
}
}
}
//实现图的深度优先遍历
void dfs(node* start)
{
if (start == nullptr)
return;
stack<node*> stk;
unordered_set<node*> visited;
stk.push(start);
visited.insert(start);
cout << start->value << " ";
while (!stk.empty())
{
node* cur = stk.top();
bool found = false;//标记是否找到过尚未访问的后继节点
for (node* next : cur->nexts)
{
if (visited.find(next) == visited.end()) {
stk.push(next);
visited.insert(next);
cout << next->value << endl;
found = true;
break;
}
}//找到一个节点就跳出来了
if (!found)
{
stk.pop();
}
}
}
4图的拓扑排序
最简单做法:用入度为0,然后把这个点影响彻底去掉
#include <queue>
using namespace std;
class node {
public:
int value;
int in;
vector<node*> nexts;
node(int val) : value(val), in(0) {}
};
class graph {
public:
unordered_map<int, node*> nodes;
graph() {}
vector<node*> sortedTopology()
{
unordered_map<node*, int> map;
queue<node*> q;
for (auto& entry : nodes)
{
node* no = entry.second;
map[no] = no->in;
if (no->in == 0)
{
q.push(no);
}
}
vector<node*> result;
while (!q.empty())
{
node* cur = q.front();
q.pop();
result.push_back(cur);
for (node* next : cur->nexts)
{
map[next]--;//把该点的影响都消除
if (map[next] == 0)
{
q.push(next);
}
}
}
return result;
}
};其他数据结构表示时的拓扑序
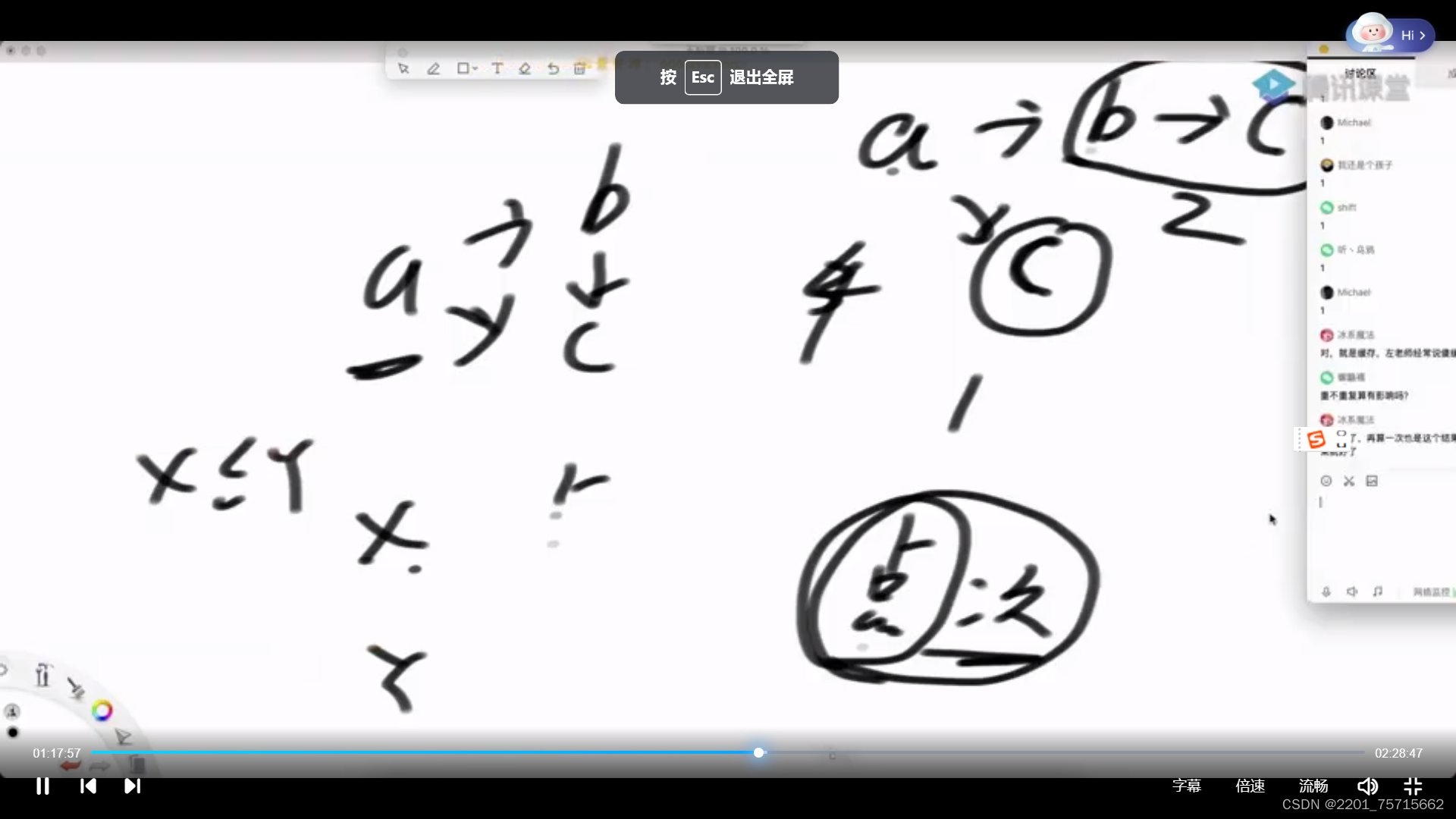
//一个点的“点次”比另一个大,说明拓扑序列一定在前面
//rocord缓存已经经过的点的点次
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
class DirectedGraphNode {
public:
int label;
vector<DirectedGraphNode*> neighbors;
DirectedGraphNode(int x) : label(x) {}
};
class Record {
public:
DirectedGraphNode* node;
long nodes;
Record(DirectedGraphNode* n, long o) : node(n), nodes(o) {}
};
class MyComparator {
public:
bool operator() (const Record& o1, const Record& o2) const {
return o1.nodes == o2.nodes ? 0 : (o1.nodes > o2.nodes ? -1 : 1);
}
};
Record f(DirectedGraphNode* cur, unordered_map<DirectedGraphNode*, Record>& order) {
if (order.find(cur) != order.end()) {
return order[cur];
}
long nodes = 0;
for (DirectedGraphNode* next : cur->neighbors) {
nodes += f(next, order).nodes;
}
Record ans(cur, nodes + 1);
order[cur] = ans;
return ans;
}
vector<DirectedGraphNode*> topSort(vector<DirectedGraphNode*>& graph) {
unordered_map<DirectedGraphNode*, Record> order;
for (DirectedGraphNode* cur : graph) {
f(cur, order);
}
vector<Record> recordArr;
for (auto& entry : order) {
recordArr.push_back(entry.second);
}
sort(recordArr.begin(), recordArr.end(), MyComparator());
vector<DirectedGraphNode*> ans;
for (Record& r : recordArr) {
ans.push_back(r.node);
}
return ans;
}//用比较深度的方法来求拓扑序
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
class DirectedGraphNode {
public:
int label;
vector<DirectedGraphNode*> neighbors;
DirectedGraphNode(int x) : label(x) {}
};
class Record {
public:
DirectedGraphNode* node;
int deep;
Record(DirectedGraphNode* n, int o) : node(n), deep(o) {}
};
class MyComparator {
public:
bool operator() (const Record& o1, const Record& o2) const {
return o2.deep - o1.deep;
}
};
Record f(DirectedGraphNode* cur, unordered_map<DirectedGraphNode*, Record>& order) {
if (order.find(cur) != order.end()) {
return order[cur];
}
int follow = 0;
for (DirectedGraphNode* next : cur->neighbors) {
follow = max(follow, f(next, order).deep);
}
Record ans(cur, follow + 1);
order[cur] = ans;
return ans;
}
vector<DirectedGraphNode*> topSort(vector<DirectedGraphNode*>& graph) {
unordered_map<DirectedGraphNode*, Record> order;
for (DirectedGraphNode* cur : graph) {
f(cur, order);
}
vector<Record> recordArr;
for (auto& entry : order) {
recordArr.push_back(entry.second);
}
sort(recordArr.begin(), recordArr.end(), MyComparator());
vector<DirectedGraphNode*> ans;
for (Record& r : recordArr) {
ans.push_back(r.node);
}
return ans;
}
5 克鲁斯卡尔算法求最小生成树
用并查集实现,每次从小的边开始选,如果这个边能形成环(也就是说这条边的两个端点已经在集合里面存在了)就不要这条边,不能的话就要
#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>
#include <queue>
#include <stack>
#include <algorithm>
using namespace std;
class Node {
public:
int value;
Node(int x) : value(x) {}
};
class Edge {
public:
int weight;
Node* from;
Node* to;
Edge(int w, Node* f, Node* t) : weight(w), from(f), to(t) {}
};
class UnionFind {
private:
unordered_map<Node*, Node*> fatherMap;
unordered_map<Node*, int> sizeMap;
public:
UnionFind() {}
void makeSets(const vector<Node*>& nodes) {
fatherMap.clear();
sizeMap.clear();
for (Node* node : nodes) {
fatherMap[node] = node;
sizeMap[node] = 1;
}
}
Node* findFather(Node* n) {
stack<Node*> path;
while (n != fatherMap[n]) {
path.push(n);
n = fatherMap[n];
}
while (!path.empty()) {
fatherMap[path.top()] = n;
path.pop();
}
return n;
}
bool isSameSet(Node* a, Node* b) {
return findFather(a) == findFather(b);
}
void unionSets(Node* a, Node* b) {
if (!a || !b) {
return;
}
Node* aDai = findFather(a);
Node* bDai = findFather(b);
if (aDai != bDai) {
int aSetSize = sizeMap[aDai];
int bSetSize = sizeMap[bDai];
if (aSetSize <= bSetSize) {
fatherMap[aDai] = bDai;
sizeMap[bDai] += aSetSize;
sizeMap.erase(aDai);
} else {
fatherMap[bDai] = aDai;
sizeMap[aDai] += bSetSize;
sizeMap.erase(bDai);
}
}
}
};
class EdgeComparator {
public:
bool operator() (const Edge& o1, const Edge& o2) const {
return o1.weight > o2.weight; // 改为从大到小排序
}
};
unordered_set<Edge> kruskalMST(const vector<Edge>& edges, const vector<Node*>& nodes) {
UnionFind unionFind;
unionFind.makeSets(nodes);
priority_queue<Edge, vector<Edge>, EdgeComparator> priorityQueue;
for (const Edge& edge : edges) {
priorityQueue.push(edge);
}
unordered_set<Edge> result;
while (!priorityQueue.empty()) {
Edge edge = priorityQueue.top();
priorityQueue.pop();
if (!unionFind.isSameSet(edge.from, edge.to)) {
result.insert(edge);
unionFind.unionSets(edge.from, edge.to);
}
}
return result;
}
6 prim算法
从某一个点开始,选一个最小的边,同时把相连的点解锁,同时这两个点找最小的边
周而复始
#include <iostream>
#include <vector>
#include <set>
#include <queue>
#include <climits>
using namespace std;
class Edge {
public:
int weight;
Node* from;
Node* to;
Edge(int w, Node* f, Node* t) : weight(w), from(f), to(t) {}
};
class EdgeComparator {
public:
bool operator() (const Edge& o1, const Edge& o2) const {
return o1.weight > o2.weight; // 改为从大到小排序
}
};
set<Edge> primMST(Graph& graph) {
// 解锁的边进入小根堆
priority_queue<Edge, vector<Edge>, EdgeComparator> priorityQueue;
// 哪些点被解锁出来了
set<Node*> nodeSet;
set<Edge> result; // 依次挑选的的边在result里
for (auto& it : graph.nodes) { // 随便挑了一个点
Node* node = it.second;
// node 是开始点
if (nodeSet.find(node) == nodeSet.end()) {
nodeSet.insert(node);
for (Edge* edge : node->edges) { // 由一个点,解锁所有相连的边
priorityQueue.push(*edge);
}
while (!priorityQueue.empty()) {
Edge edge = priorityQueue.top(); // 弹出解锁的边中,最小的边
priorityQueue.pop();
Node* toNode = edge.to; // 可能的一个新的点
if (nodeSet.find(toNode) == nodeSet.end()) { // 不含有的时候,就是新的点
nodeSet.insert(toNode);
result.insert(edge);
for (Edge* nextEdge : toNode->edges) {
priorityQueue.push(*nextEdge);
}
}
}
}
// break;//这里是防森林用的,如果确定只有一个图就注释掉
}
return result;
}
// 请保证graph是连通图
// graph[i][j]表示点i到点j的距离,如果是系统最大值代表无路
// 返回值是最小连通图的路径之和
int prim(vector<vector<int>>& graph) {
int size = graph.size();
vector<int> distances(size, INT_MAX);
vector<bool> visit(size, false);
visit[0] = true;
for (int i = 0; i < size; i++) {
distances[i] = graph[0][i];
}
int sum = 0;
for (int i = 1; i < size; i++) {
int minPath = INT_MAX;
int minIndex = -1;
for (int j = 0; j < size; j++) {
if (!visit[j] && distances[j] < minPath) {
minPath = distances[j];
minIndex = j;
}
}
if (minIndex == -1) {
return sum;
}
visit[minIndex] = true;
sum += minPath;
for (int j = 0; j < size; j++) {
if (!visit[j] && distances[j] > graph[minIndex][j]) {
distances[j] = graph[minIndex][j];
}
}
}
return sum;
}
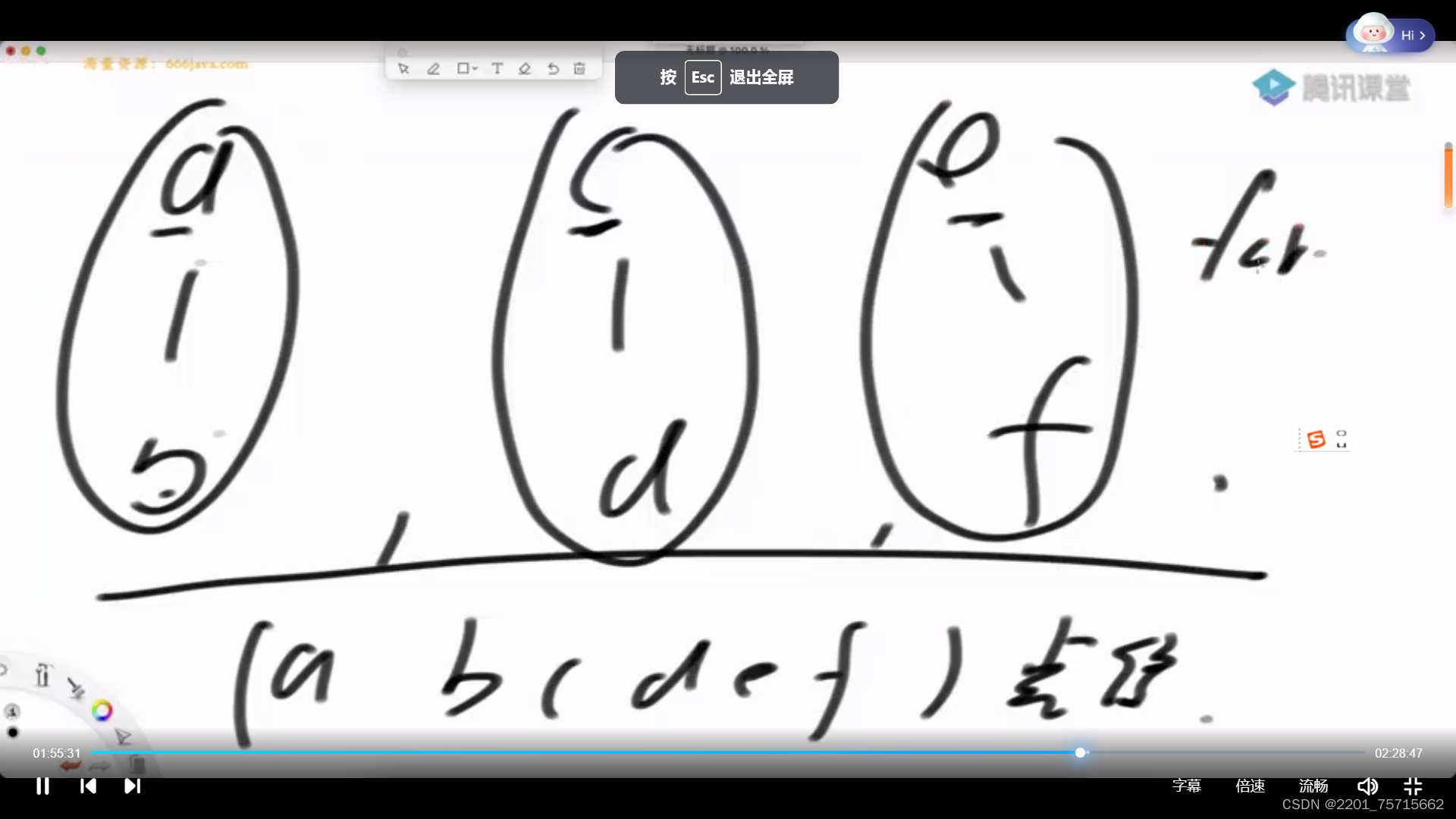
7单元最短路径算法Dijkstra
给一个点,求出他能到达的所有点最小值,到不了的为无穷
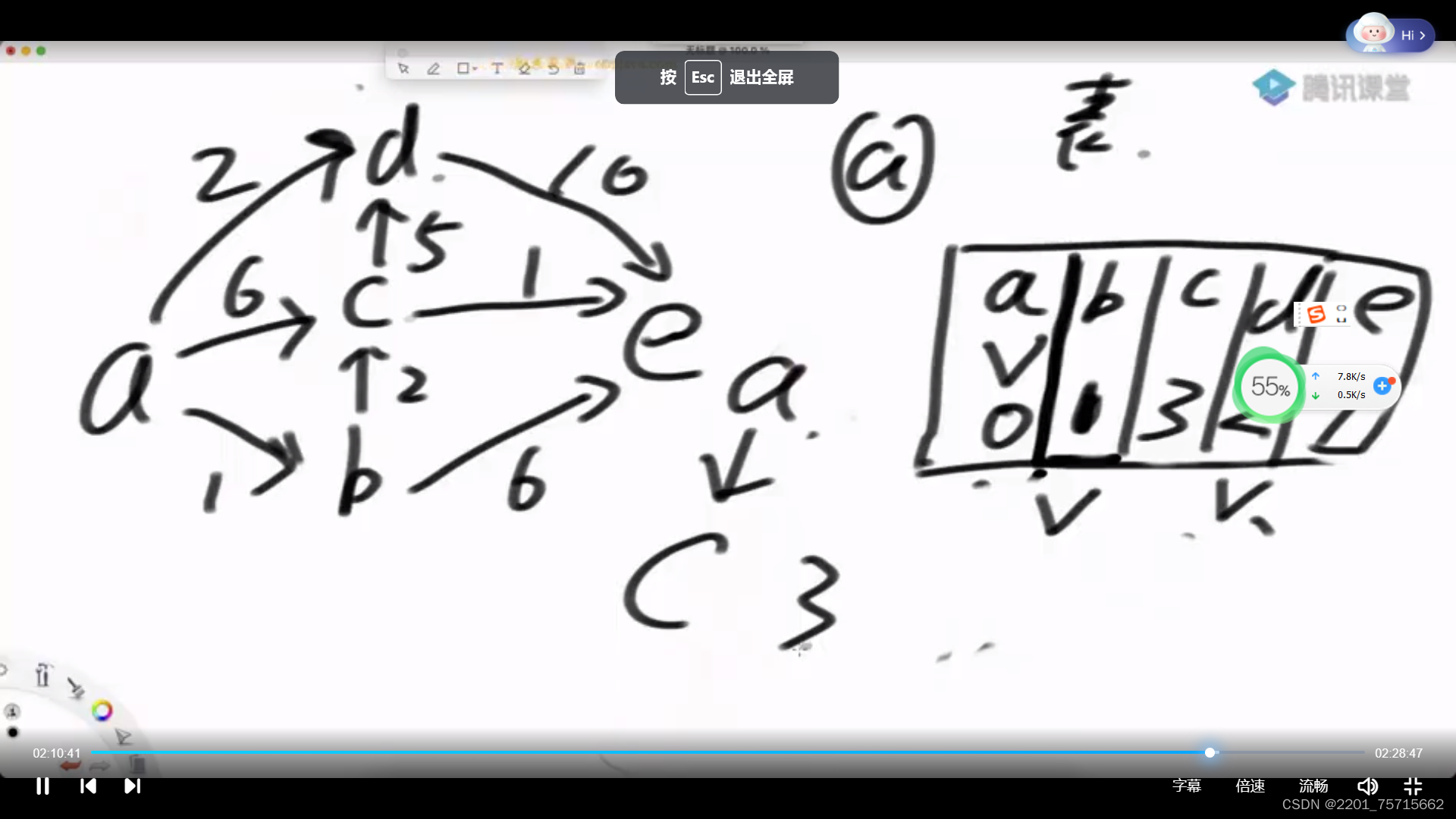
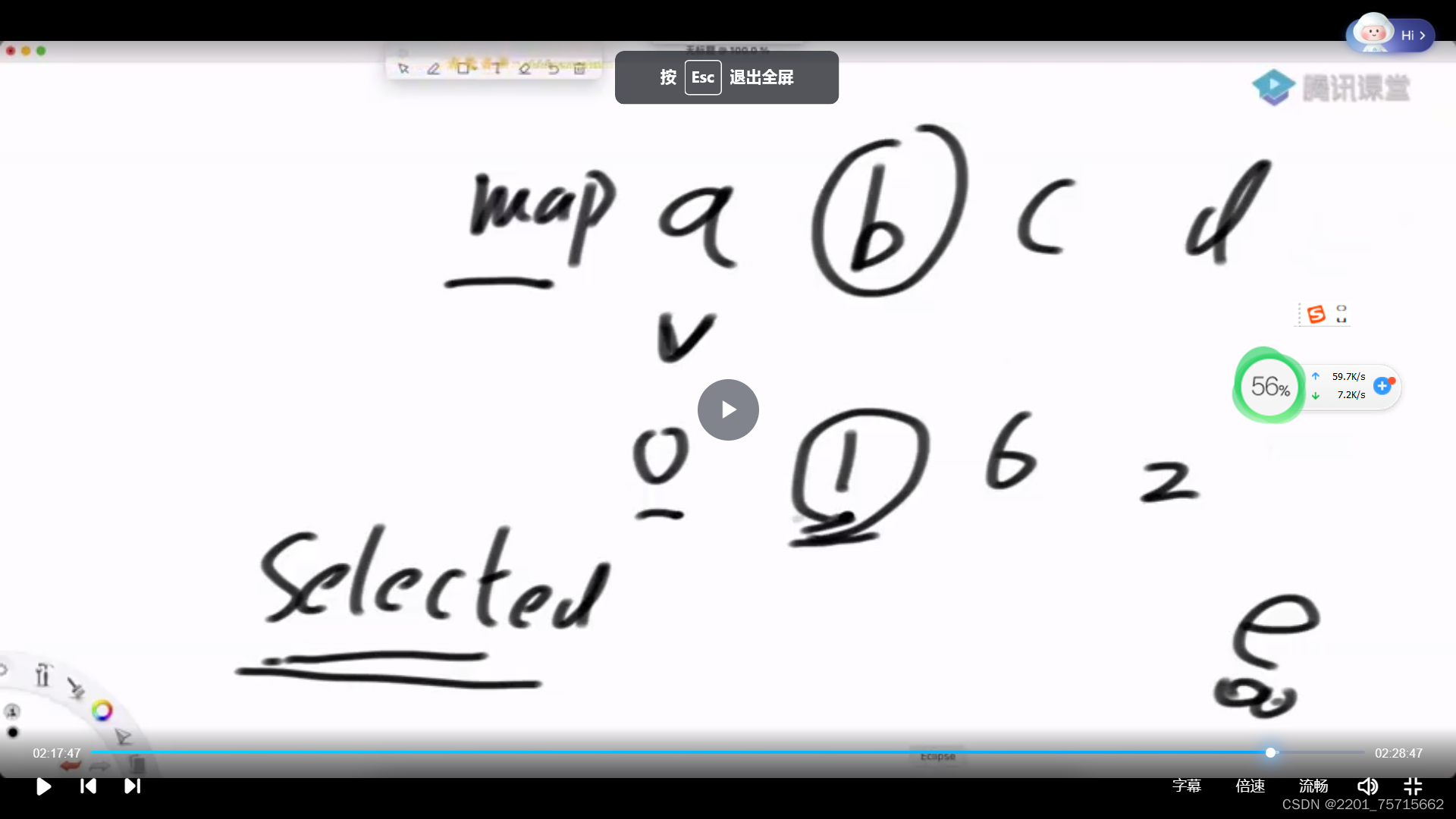 要标记所有已经选过的点,不能再选,慢的原因是不停遍历所有点选最小
要标记所有已经选过的点,不能再选,慢的原因是不停遍历所有点选最小
还有用加强堆的优化
小根堆根据距离的大小组织,每次弹出堆顶,然后更新堆中元素,由于需要找到对应的点,所以必须用加强堆做

#include <iostream>
#include <vector>
#include <unordered_map>
#include <unordered_set>
#include <limits>
using namespace std;
// 前向声明类
class Node;
class Edge;
// 定义边(Edge)类
class Edge {
public:
Node* to; // 指向的节点
int weight; // 边的权重
Edge(Node* t, int w) : to(t), weight(w) {} // 构造函数
};
// 定义节点(Node)类
class Node {
public:
vector<Edge> edges; // 该节点连接的边
};
// Dijkstra算法实现,不考虑负权重
class Code01_Dijkstra {
public:
// 使用哈希表实现的Dijkstra算法
static unordered_map<Node*, int> dijkstra1(Node* from) {
// 用起始节点初始化距离映射
unordered_map<Node*, int> distanceMap;
distanceMap[from] = 0;
// 用于存储已选择节点的集合
unordered_set<Node*> selectedNodes;
// 查找具有最小距离且尚未选择的节点
Node* minNode = getMinDistanceAndUnselectedNode(distanceMap, selectedNodes);
// 直到所有节点都被选择为止
while (minNode != nullptr) {
int distance = distanceMap[minNode];
// 更新相邻节点的距离
for (Edge& edge : minNode->edges) {
Node* toNode = edge.to;
if (distanceMap.find(toNode) == distanceMap.end()) {
distanceMap[toNode] = distance + edge.weight;
} else {
distanceMap[toNode] = min(distanceMap[toNode], distance + edge.weight);
}
}
// 标记当前节点为已选择
selectedNodes.insert(minNode);
// 查找下一个具有最小距离的节点
minNode = getMinDistanceAndUnselectedNode(distanceMap, selectedNodes);
}
return distanceMap;
}
// 获取未选择节点中距离最小的节点
static Node* getMinDistanceAndUnselectedNode(unordered_map<Node*, int>& distanceMap, unordered_set<Node*>& touchedNodes) {
Node* minNode = nullptr;
int minDistance = numeric_limits<int>::max();
for (auto& entry : distanceMap) {
Node* node = entry.first;
int distance = entry.second;
if (touchedNodes.find(node) == touchedNodes.end() && distance < minDistance) {
minNode = node;
minDistance = distance;
}
}
return minNode;
}
};
#include <iostream>
#include <vector>
#include <unordered_map>
#include <limits>
using namespace std;
// 前向声明类
class Node;
class Edge;
class NodeRecord;
class NodeHeap;
// 定义边(Edge)类
class Edge {
public:
Node* to; // 指向的节点
int weight; // 边的权重
Edge(Node* t, int w) : to(t), weight(w) {} // 构造函数
};
// 定义节点(Node)类
class Node {
public:
vector<Edge> edges; // 该节点连接的边
};
// 定义节点记录(NodeRecord)类
class NodeRecord {
public:
Node* node; // 节点
int distance; // 距离
NodeRecord(Node* n, int d) : node(n), distance(d) {} // 构造函数
};
// 定义节点堆(NodeHeap)类
class NodeHeap {
private:
Node** nodes; // 实际的堆结构
unordered_map<Node*, int> heapIndexMap; // key: 节点, value: 堆中的位置
unordered_map<Node*, int> distanceMap; // key: 节点, value: 从源节点出发到该节点的目前最小距离
int size; // 堆上有多少个点
public:
NodeHeap(int s) : size(s) {
nodes = new Node*[size];
}
bool isEmpty() {
return size == 0;
}
// 有一个点叫node,现在发现了一个从源节点出发到达node的距离为distance
// 判断要不要更新,如果需要的话,就更新
void addOrUpdateOrIgnore(Node* node, int distance) {
if (inHeap(node)) {
distanceMap[node] = min(distanceMap[node], distance);
insertHeapify(node, heapIndexMap[node]);
}
if (!isEntered(node)) {
nodes[size] = node;
heapIndexMap[node] = size;
distanceMap[node] = distance;
insertHeapify(node, size++);
}
}
NodeRecord pop() {
NodeRecord nodeRecord = NodeRecord(nodes[0], distanceMap[nodes[0]]);
swap(0, size - 1);
heapIndexMap[nodes[size - 1]] = -1;
distanceMap.erase(nodes[size - 1]);
delete nodes[size - 1]; // C++ 需要手动释放内存
nodes[size - 1] = nullptr;
heapify(0, --size);
return nodeRecord;
}
private:
void insertHeapify(Node* node, int index) {
while (distanceMap[nodes[index]] < distanceMap[nodes[(index - 1) / 2]]) {
swap(index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
void heapify(int index, int size) {
int left = index * 2 + 1;
while (left < size) {
int smallest = left + 1 < size && distanceMap[nodes[left + 1]] < distanceMap[nodes[left]]
? left + 1
: left;
smallest = distanceMap[nodes[smallest]] < distanceMap[nodes[index]] ? smallest : index;
if (smallest == index) {
break;
}
swap(smallest, index);
index = smallest;
left = index * 2 + 1;
}
}
bool isEntered(Node* node) {
return heapIndexMap.find(node) != heapIndexMap.end();
}
bool inHeap(Node* node) {
return isEntered(node) && heapIndexMap[node] != -1;
}
void swap(int index1, int index2) {
heapIndexMap[nodes[index1]] = index2;
heapIndexMap[nodes[index2]] = index1;
Node* tmp = nodes[index1];
nodes[index1] = nodes[index2];
nodes[index2] = tmp;
}
};
// 改进后的Dijkstra算法
// 从head出发,生成到达每个节点的最小路径记录并返回
unordered_map<Node*, int> dijkstra2(Node* head, int size) {
NodeHeap nodeHeap(size);
nodeHeap.addOrUpdateOrIgnore(head, 0);
unordered_map<Node*, int> result;
while (!nodeHeap.isEmpty()) {
NodeRecord record = nodeHeap.pop();
Node* cur = record.node;
int distance = record.distance;
for (Edge& edge : cur->edges) {
nodeHeap.addOrUpdateOrIgnore(edge.to, edge.weight + distance);
}
result[cur] = distance;
}
return result;
}