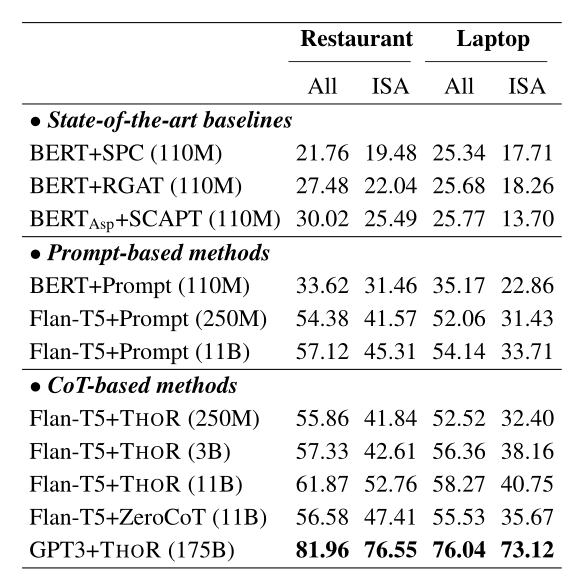
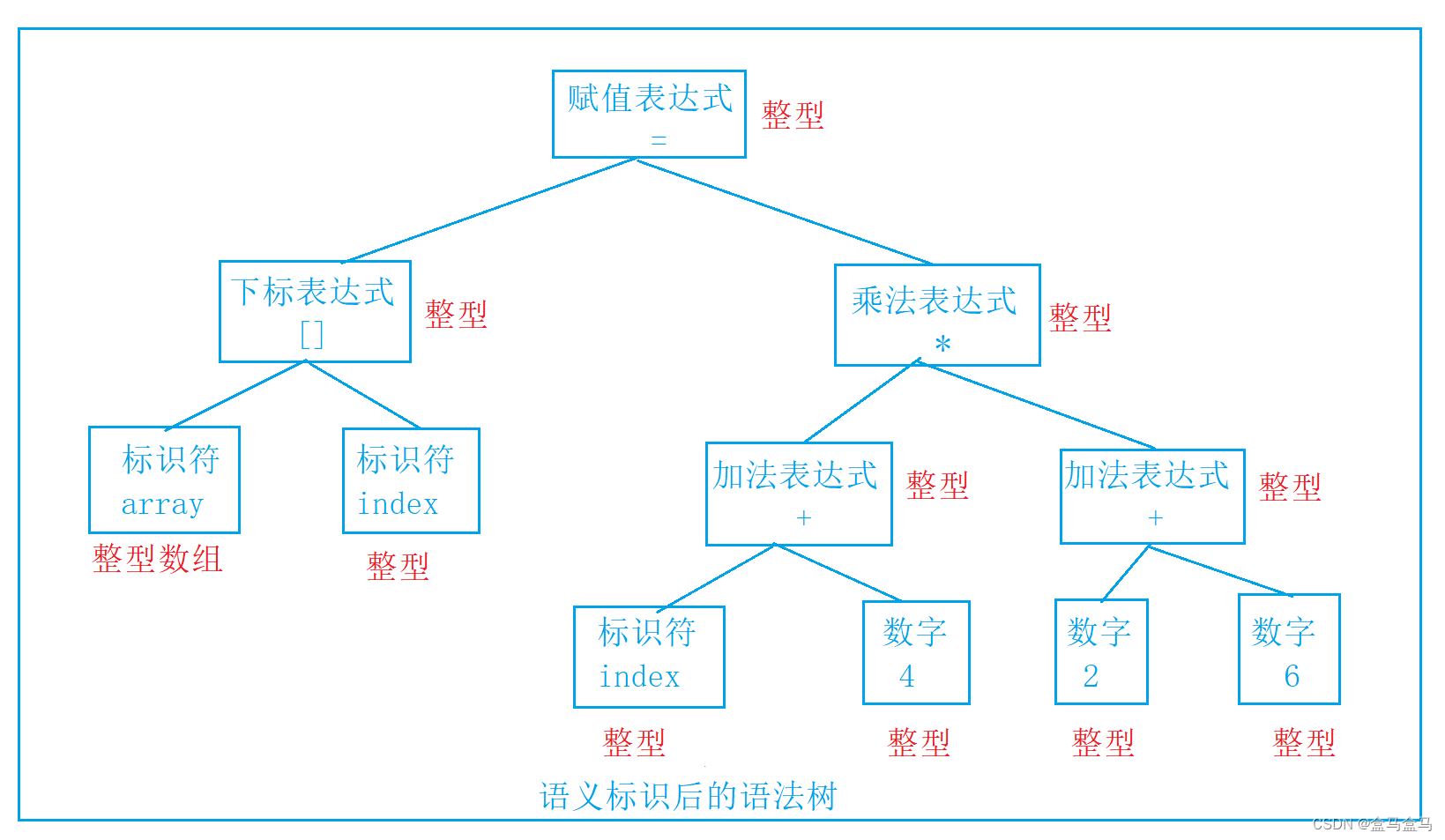
我这里主要写代码,定义等参考图论基础和表示 | 菜鸟教程
一、邻接矩阵代码实现
java">public class AdjacencyMatrix {
private int n;//节点数
private int m;//边数
private boolean directed;//是否为有向图
private int[][] data;//图数据
// 构造一个没有边的邻接矩阵
public AdjacencyMatrix(int n, boolean directed) {
// g初始化为n*n的布尔矩阵, 每一个data[i][j]均为0, 表示没有任何边,权值为0
// 为非零正整数时表示有边且边的权值为该值
assert n>=0;
this.n = n;
this.directed = directed;
this.m=0;
data=new int[n][n];
}
//判断v到w是否有边
private boolean hasEdge(int v,int w){
assert v>=0 && v<n;
assert w>=0 && w<n;
// 为非零正整数时表示有边且边的权值为该值
return data[v][w]>0;
}
//给v到w添加边和权值
private void addEdge(int v,int w,int weight){
assert v>=0 && v<n;
assert w>=0 && w<n;
if (hasEdge(v,w)){
return;
}
data[v][w]=weight;
if (v!=w &&!directed){
data[w][v]=weight;
};
m++;
}
//遍历邻边,通过一个顶点遍历相关的邻边
public Vector<Integer> adjacentEdge(int v) {
assert v >= 0 && v < n;
Vector<Integer> ae = new Vector<>();
for (int i=0;i<n;i++) {
if (data[v][i] > 0) {
ae.add(i);
}
}
return ae;
}
// 返回节点个数
public int nodeNum(){ return n;}
// 返回边的个数
public int edgeNum(){ return m;}
}
二、邻接表代码实现
java">public class AdjacencyList {
private int n;//节点数
private int m;//边数
private boolean directed;//是否为有向图
//Vector是线程安全的可变数组
private Vector<Integer>[] data;
public AdjacencyList(int n, boolean directed) {
this.n = n;
this.directed = directed;
data = new Vector[n];
for (int i=0;i<n;i++){
data[i]=new Vector<Integer>();
}
}
//判断v到w是否有边
private boolean hasEdge(int v,int w){
assert v>=0 && v<n;
assert w>=0 && w<n;
// 为非零正整数时表示有边且边的权值为该值
/*for (int i=0;i<data[v].size();i++ ) {
if (data[v].elementAt(i)==w){
return true;
}
}*/
if (data[v].contains(w)){
return true;
}
return false;
}
//给v到w添加边和权值
private void addEdge(int v,int w,int weight){
assert v>=0 && v<n;
assert w>=0 && w<n;
if (data[v].contains(w)){
return;
}
data[v].add(w);
if (v!=w && !directed){
data[w].add(v);
}
m++;
}
//遍历邻边,通过一个顶点遍历相关的邻边
public Vector<Integer> adjacentEdge(int v) {
assert v>=0 && v<n;
return data[v];
}
// 返回节点个数
public int nodeNum(){ return n;}
// 返回边的个数
public int edgeNum(){ return m;}
}
三、深度优先遍历(搜索)DBF
DFS(Depth-First-Search,深度优先遍历)算法的具体做法是:
从某个点一直往深处走,走到不能往下走之后,就回退到上一步,直到找到解或把所有点走完
java">public class DFS{
public AdjacencyMatrix matrix;
private int count;//连通分量数
private int[] id;//每个节点分量标记id
private boolean[] visited;//记录节点是否被遍历过
private int nodeNum;
//构造函数:算法初始化
public DFS(AdjacencyMatrix matrix) {
this.nodeNum=matrix.nodeNum();
this.matrix = matrix;
this.count=0;
this.id=new int[nodeNum];
this.visited=new boolean[nodeNum];
for (int i=0;i<nodeNum;i++){
visited[i]=false;
id[i]=-1;
}
//使用doDFS方法获取连通分量数
for (int i=0;i< nodeNum;i++){
if (!visited[i]){
count++;
this.doDFS(i);
}
}
}
private void doDFS(int node){
visited[node]=true;
id[node]=count;
//使用递归遍历节点的边
for (Integer i: matrix.adjacentEdge(node)){
if(!visited[i]){
doDFS(i);
}
}
}
public int getCount() {
return count;
}
// 查询点v和点w是否联通
//两个节点拥有相同的 id 值代表属于同一联通分量。
private boolean isConnected( int v , int w ){
assert v >= 0 && v < nodeNum;
assert w >= 0 && w < nodeNum;
return id[v] == id[w];
}
}
四、寻路算法
java">public class LookPath {
AdjacencyMatrix matrix;
private int nodeNum;
private int start;//起点
private boolean[] visited;//记录dfs的过程中节点是否被访问
private int[] last;// 记录路径, last[i]表示查找的路径上i的上一个节点
public LookPath(AdjacencyMatrix matrix, int start) {
this.matrix = matrix;
this.start = start;
this.nodeNum= matrix.nodeNum();
assert start >= 0 && start < nodeNum;
visited=new boolean[nodeNum];
last=new int[nodeNum];
for (int i=0;i<nodeNum;i++){
visited[i]=false;
last[i]=-1;
}
doDFS(start);
}
// 图的深度优先遍历
private void doDFS(int v){
assert v >= 0 && v < nodeNum;
visited[v]=true;
for (Integer i: matrix.adjacentEdge(v)){
last[i]=v;
doDFS(i);
}
}
//判断start节点到end节点是否有路径,只要查询 visited 对应数组值即可。
private boolean hasPath(int end){
assert end >= 0 && end < nodeNum;
return visited[end];
}
private Vector<Integer> lookPath(int current){
assert hasPath(current);
Stack<Integer> stack=new Stack<>();// 通过from数组查找到从current到start的路径, 存放到栈中
while (current!=-1){
stack.push(current);
current=last[current];
}
// 从栈中依次取出元素, 获得顺序的从start到current的路径
Vector<Integer> ve = new Vector<>();
while (!stack.empty()){
ve.addElement(stack.pop());
}
return ve;
}
// 打印出从s点到w点的路径
public void showPath(int w){
assert hasPath(w) ;
Vector<Integer> vec = lookPath(w);
for( int i = 0 ; i < vec.size() ; i ++ ){
System.out.print(vec.elementAt(i));
if( i == vec.size() - 1 )
System.out.println();
else
System.out.print(" -> ");
}
}
}
五、广度优先遍历与最短路径
(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点“死磕到底“的思维不同,广度优先算法关注的重点在于每一层的结点进行的下一层的访问。类似于二叉树或堆的层序遍历,BFS的核心就是要把当前在哪作为一个状态存储,并将这个状态交给队列进行入队操作
java">public class BFS {
AdjacencyMatrix matrix;
private int nodeNum;
private int start;//起点
private boolean[] visited;//记录dfs的过程中节点是否被访问
private int[] last;// 记录路径, last[i]表示查找的路径上i的上一个节点
private int[] order;// 记录路径中节点的次序。order[i]表示i节点在路径中的次序。
public BFS(AdjacencyMatrix matrix, int start) {
this.matrix = matrix;
this.start = start;
this.nodeNum = matrix.nodeNum();
assert start >= 0 && start < nodeNum;
visited=new boolean[nodeNum];
last=new int[nodeNum];
order=new int[nodeNum];
for (int i=0;i<nodeNum;i++){
visited[i]=false;
last[i]=-1;
order[i]=-1;
}
doBFS(start);
}
// 图的深度优先遍历
private void doBFS(int v){
visited[v]=true;
order[v]=0;
LinkedList<Integer> queue=new LinkedList<>();
//add向链表末尾后添加,push向第一个位置前添加,pop返回并删除第一个,当队列或栈使用时要得当
queue.addFirst(v);
while (!queue.isEmpty()){
Integer rf = queue.removeFirst();
for (Integer i : matrix.adjacentEdge(rf)) {
last[i]=rf;
queue.addLast(i);
visited[i]=true;
order[i]=order[rf]+1;
}
}
}
//判断start节点到end节点是否有路径,只要查询 visited 对应数组值即可。
private boolean hasPath(int end){
assert end >= 0 && end < nodeNum;
return visited[end];
}
private Vector<Integer> lookPath(int current){
assert hasPath(current);
Stack<Integer> stack=new Stack<>();// 通过from数组查找到从current到start的路径, 存放到栈中
while (current!=-1){
stack.push(current);
current=last[current];
}
// 从栈中依次取出元素, 获得顺序的从start到current的路径
Vector<Integer> ve = new Vector<>();
while (!stack.empty()){
ve.addElement(stack.pop());
}
return ve;
}
// 打印出从s点到w点的路径
public void showPath(int w){
assert hasPath(w) ;
Vector<Integer> vec = lookPath(w);
for( int i = 0 ; i < vec.size() ; i ++ ){
System.out.print(vec.elementAt(i));
if( i == vec.size() - 1 )
System.out.println();
else
System.out.print(" -> ");
}
}
// 查看从s点到w点的最短路径长度
// 若从s到w不可达,返回-1
public int length(int w){
assert w >= 0 && w < nodeNum;
return order[w];
}
}