文章目录
- 深度优先搜索
- 广度优先搜索
- 树和图的存储
- 图的深搜
- 拓扑序
- 深搜练习题
- 842. 排列数字
- 843. n-皇后问题
- 广搜练习题
- 844. 走迷宫
- 845. 八数码
- 树和图的存储与遍历练习题
- 846. 树的重心
- 847. 图中点的层次
- 拓扑序练习题
- 848. 有向图的拓扑序列
深度优先搜索
数据结构: stack,利用函数调用的函数栈,不用自己实现
空间:O(h)
不具有最短性
深搜没有模板,主要理解思想:一条路走到黑,走不下去了就进行回溯
其中树的先序遍历就是一种深搜
广度优先搜索
数据结构:queue,空间O( 2 h 2^h 2h)
最短路问题包含dp问题,dp是一类特殊的BFS,dp问题中,图没有环
只有边权都是1时,才用BFS,其他问题有专门的最短路方法,因为使用BFS的时间复杂度高
模板:
初始化queue;
while queue 不为空
{
取出队头t;
扩展t;
}
树和图的存储
树是一种特殊的图,无环连通图
无向图是一种特殊的有向图,存储两条有向边即可,所以只要会写有向图就能写无向图,也能写树
有向图的存储:邻接矩阵,空间复杂度O(
n
2
n^2
n2),使用比较少,该结构主要用来存储稠密图
邻接表:用得最多,每个节点开个单链表,存储与该点邻接的点
邻接表的插入一般是头插,因为头插快
图的深搜
如何用数据结构表示图?
假设无向图中有N个节点,并且只有N - 1条边
对于图中某个节点,使用一张单链表存储与其直接相连的节点。h[N]存储所有单链表的头指针,所有单链表组成了图的邻接表。h数组具体存储的是e数组以及ne数组的索引,可以将这些索引看成边的编号
通过h数组可以获取某一点的单链表,其实是获取了某一点的一条边的编号
如何索引h数组?图中每个点都能作为一个索引,对图中的每个点进行编号,用编号索引h数组,得到邻接该点的边的idx(编号)
小总结下:用点的编号索引h数组,获取e和ne数组的索引(边的编号)
ne数组为指针域,存储下一条边的编号
e数组为数据域,表示一条边,但其存储该条边的一个点(编号),另外一个点呢?
用点的编号索引h数组,得到邻接该点的边,而表示边的e数组存储了另一个点的编号
这两个点共同表示一条边
图的深搜模板:
const int N = 1e5 + 10, M = N * 2;
int h[N], e[M], ne[M], idx;
bool vt[N];
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
void dfs(int u)
{
vt[u] = true;
for (int i = h[u]; i != -1; i = ne[i])
{
int t = e[i];
if (!vt[t]) dfs(t);
}
}
总结:
假设图中有n个节点,每个点都被抽象(映射)为编号1~n
用点的编号索引h数组获取边的编号,用边的编号索引e和ne数组,e数组存储点的编号,ne数组存储边的编号,指向邻接表中,当前边的下一条边
拓扑序
只有有向图具有拓扑序列,无向图没有
对于图中的每条边,拓扑序列中,起点出现在终点前面
若图存在环,则没有拓扑序。有向无环图一定存在拓扑序列,因此有向无环图也被称为拓扑图
一个无环图,一定至少存在一个入度为0的点。可以用反证法证明:
即一个无向图,每个点的入度都不为0,那么从一个点开始,通过其入边能找到这条的起点,此时已经遍历了图中的2个点
假设图中有n个点,当遍历点的数量达到n + 1时,说明肯定遍历了同一个点两次,即图中存在一条路径能够遍历某个点两次
所以图中存在环,反证无向图中,每个点的入度都为0
注意:拓扑序列不唯一,如何获取有向无环图的其中一个拓扑序列?
使用广搜,将所有入度为0的点入队,将出队的点尾插到拓扑序列中(因为入度为0的点不是点的终点,所以入度为0的点可以放在拓扑序列的前面)
枚举队头的所有出边,假设队头表示的点为t,删除队头的所有出边,假设出边的终点是u,即删除t->u
假设d数组表示点的出边数量,若d[u]为0,则将u入队。因为u入队后,在其之前的点要么是u的起点,要么和u没有关系。入队后依然满足拓扑关系
模板:
bool topsort()
{
int hh = 0, tt = -1;
for (int i = 0; i < n; ++ i )
if (!d[i]) q[++ tt] = i;
while (hh <= tt)
{
int u = q[hh ++ ];
for (int i = h[u]; i != -1; i = ne[i])
{
int t = e[i];
if (-- d[t] == 0) q[++ tt] = t;
}
}
return tt == n - 1;
}
topsort返回该图是否能构成拓扑序列,假设队列没有出队操作,最后的队列长度等于图中点的个数时,说明该图能构成拓扑序列
因为队列的模拟是假删除,所以输出拓扑序列时,可以打印队列中哪些“被删除的元素”
深搜练习题
842. 排列数字
842. 排列数字 - AcWing题库
经典深搜问题,假设现在有n个空位,现需要将每个空位填上数字
顺序搜索所有数字,对搜索过的数字进行标记,防止数字重复
每次选择未访问过的数字到空位上,直到所有空位被填满
当所有空位被填满时,试着从最后开始拿走已经填过的数并删除访问标记,再顺序搜索剩下的数字,试着将未访问过的数字填入空位以构成新的排列
#include <iostream>
using namespace std;
const int N = 10;
int path[N];
bool vt[N];
int n;
void dfs(int u)
{
if (u == n + 1)
{
for (int i = 1; i <= n; ++ i ) printf("%d ", path[i]);
printf("\n");
}
for (int i = 1; i <= n; ++ i )
{
if (!vt[i])
{
path[u] = i;
vt[i] = true;
dfs(u + 1);
vt[i] = false;
}
}
}
int main()
{
scanf("%d", &n);
dfs(1);
return 0;
}
debug:当所有数字满足条件输出时,不应该写if (u == n),而应该写if (u == n + 1)
843. n-皇后问题
843. n-皇后问题 - AcWing题库
深搜矩阵中的每一个点,若当前位置可以放皇后,此时有放与不放两种选择尝试这两种选择。不论哪种选择都要维护最后需要输出的棋盘
若当前位置位于的行超过了矩阵的行,对矩阵的遍历结束,此时判断已经放置的皇后数量与题目要求的是否相等,若相等则输出棋盘
其实这道题与排列数字类似:
- 排列数字需要将数字放置在空位上,n皇后问题需要将皇后放置在棋盘上
- 放置数字时需要判断当前数字是否已经放置过,放置皇后时需要判断同一条线上是否有其他皇后
- 两题中,每次搜索时都需要判断已经放置的物品数量是否满足题目要求的数量
其中第二个问题,“判断同一条线上是否有其他皇后”需要经过一些转换:
- 行和列是两条直线
- 斜着的线也有两条,需要根据当前位置的行与列判断当前位于哪条斜线上
x + y对应一条斜线,n - 1 - y + x对应另一条斜线
#include <iostream>
using namespace std;
const int N = 15;
bool row[N], col[N], dg[N * 2], udg[N * 2];
char g[N][N];
int n;
void dfs(int x, int y, int s)
{
if (s > n) return;
if (y == n) y = 0, x++;
if (x == n)
{
if (s == n)
{
for (int i = 0; i < n; ++ i) puts(g[i]);
puts("");
}
return;
}
g[x][y] = '.';
if (!row[x] && !col[y] && !dg[x + y] && !udg[n - 1 - y + x])
{
row[x] = col[y] = dg[x + y] = udg[n - 1 - y + x] = true;
g[x][y] = 'Q';
dfs(x, y + 1, s + 1);
g[x][y] = '.';
row[x] = col[y] = dg[x + y] = udg[n - 1 - y + x] = false;
}
dfs(x, y + 1, s);
}
int main()
{
scanf("%d", &n);
dfs(0, 0, 0);
return 0;
}
与排列数字不同的是:两者搜索的范围不同
- 排列数字每次深搜的范围为所有数字,只是加上了未访问的限制
- n皇后问题中,每次深搜的范围为为访问的位置,而不是所有的位置
其实本质都是访问未访问过的元素,只是n皇后问题中判断是否访问可以简化
从起始遍历位置开始到当前位置,n皇后问题中都是访问过的位置
排列数字中可能存在未访问过的位置,这是因为题意的不同
debug:
if (y == n) y = 0, x++中,没有y = 0- bool数组维护的是某条直线上是否放置皇后,而不是是否访问过。每个位置都能不放置皇后,只有满足特定条件才可以放置皇后
广搜练习题
844. 走迷宫
844. 走迷宫 - AcWing题库
板子题,从左上角进行bfs,用二维数组d记录起点到每个点的距离,最后返回二维数组d右下角的值即可
#include <iostream>
#include <cstring>
using namespace std;
const int N = 105;
int r, c, x, y, nx, ny;
int g[N][N], d[N][N];
int hh, tt = -1;
typedef pair<int, int> PII;
int dx[4] = {0 , 0, 1, -1}, dy[4] = {1, -1, 0 , 0};
PII q[N * N];
void bfs()
{
memset(d, -1, sizeof(d));
d[0][0] = 0;
q[++ tt] = {0 ,0};
while (hh <= tt)
{
PII t = q[hh ++ ];
for (int i = 0; i < 4; ++ i )
{
x = t.first, y = t.second;
nx = x + dx[i], ny = y + dy[i];
if (g[nx][ny] == 0 && d[nx][ny] == -1 && nx >= 0 && nx < r && ny >= 0 && ny < c)
{
q[++ tt] = {nx, ny};
d[nx][ny] = d[x][y] + 1;
}
}
}
}
int main()
{
scanf("%d%d", &r, &c);
for (int i = 0; i < r; ++ i )
{
for (int j = 0; j < c; ++ j )
scanf("%d", &g[i][j]);
}
bfs();
printf("%d", d[r - 1][c - 1]);
return 0;
}
若要求路径,对于每个点,记录它是从哪个点走来的,倒着遍历即可
845. 八数码
845. 八数码 - AcWing题库
这题能用广搜是真的骚,题目只有一个最短路信息,求最短路可以用广搜,但是这题我是一点没看出来怎么搜,看了讲解恍然大悟
将3 * 3的二维矩阵看成图中的一个点(状态),题目给定的状态就是一个起始点,最终状态就是搜索结束的点。用从起点开始搜索,并维护距离数组,第一次搜索到结束点时的距离就是题目要求的最少交换次数
用二维矩阵表示点,有一些问题:
- 状态以及距离如何表示?
- 将二维矩阵表示成一维矩阵,也就是字符串,每个点存储字符串即可
- 用哈希表:
unordered_map<string, int>表示起点到某个状态的距离,注意状态用string表示
- 状态如何拓展?
- 根据题意,x的上下左右的数字都可以走到x的位置上,此为状态拓展
- 将一维数组中的x坐标转换成3 * 3的二维矩阵中的坐标,根据上下左右四个方向向外拓展
- 若第一次遇到拓展后的状态,说明当前距离是递达该状态的最短距离,此时更新距离数组
一维坐标k转换成n * m的二维坐标x, y:x = k / n, y = k % m
反之:k = x * n + m
#include <iostream>
#include <string>
#include <queue>
#include <unordered_map>
using namespace std;
int bfs(const string& start)
{
unordered_map<string, int> d;
string end = "12345678x";
queue<string> q;
q.push(start);
d[start] = 0;
int dx[4] = { 0, 0, 1, -1 }, dy[4] = { 1, -1, 0, 0 };
while (!q.empty())
{
string u = q.front();
q.pop();
if (u == end) return d[u];
int dis = d[u];
int k = u.find('x');
int x = k / 3, y = k % 3;
for (int i = 0; i < 4; ++ i )
{
int nx = x + dx[i], ny = y + dy[i];
if (nx >= 0 && nx < 3 && ny >= 0 && ny < 3)
{
swap(u[k], u[nx * 3 + ny]);
if (!d.count(u)) d[u] = dis + 1, q.push(u);
swap(u[k], u[nx * 3 + ny]);
}
}
}
return -1;
}
int main()
{
string start;
char c;
while (cin >> c) start += c;
printf("%d\n", bfs(start));
return 0;
}
树和图的存储与遍历练习题
846. 树的重心
846. 树的重心 - AcWing题库
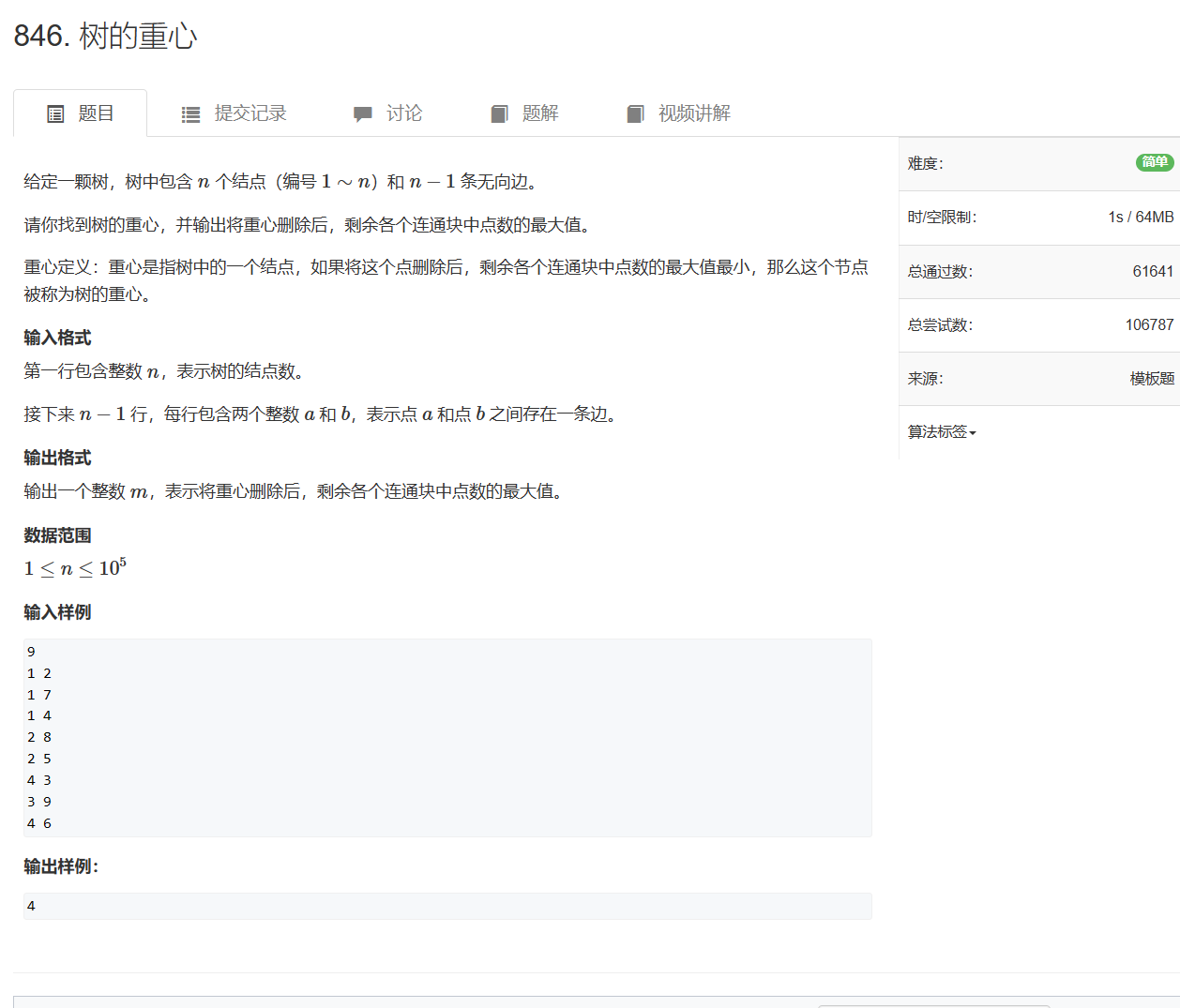
遍历树中每一个点并删除,并找到删除后的所有连通块中,拥有最大节点数量的连通块并保存该数量
遍历所有点,找到数量的最小值
删除树中的一个点后,以其子节点为根节点的树是一个连通块,有几个子节点就有几个连通块(前提是这些子节点不直接相连)
整颗树中,删除该点以及其子孙节点后,剩余节点也构成一个连通块
在深搜的过程中维护连通块的节点数量:int dfs(int u),返回以u为根节点的子树中(连通块)点的数量
在深搜的过程中,如何记录当前连通块中点的数量?
- 首先,当前搜索的点为一个数量
- 其次,对于当前点的子节点,可以将子节点作为
dfs函数的参数,得到以子节点为根的连通块数量 - 最后,将所有以子节点为根的连通块数量累加,加上自身的1,就是以当前点为根节点的连通块数量
在维护连通块数量时,还需要维护删除当前点后,所有连通块中,连通块数量的最大值
所有连通块包含两部分,一是以当前节点的子节点为根节点的连通块,以及删除当前节点与其子节点为根节点的连通块,剩下的部分也是一个连通块
根据以上连通块的数量,维护一个最大值。删除树中每一个节点,都能得到一个连通块最大值,题目要返回这些最大值中的最小值
在脑中想象递归的过程,可以发现连通块数量的计算是在弹出函数栈时完成的
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5 + 10, M = 2 * N;
int h[N], e[M], ne[M], idx;
bool vt[N];
int n, x, y, ans = N;
// sum:以u节点为根节点的连通块中点的数量
// m_s:以u节点的子节点为根的连通块数量中的最大值
// sum:以u节点的子节点为根的连通块数量总和,这是为了计算另一种连通块数量
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
int dfs(int u)
{
int sum = 1, m_s = 0;
vt[u] = true;
for (int i = h[u]; i != -1; i = ne[i])
{
int t = e[i];
if (!vt[t])
{
int s = dfs(t);
sum += s;
m_s = max(m_s, s);
}
}
m_s = max(m_s, n - sum);
ans = min(ans, m_s);
return sum;
}
int main()
{
memset(h, -1, sizeof(h));
scanf("%d", &n);
for (int i = 0; i < n - 1; ++ i )
{
scanf("%d%d", &x, &y);
add(x, y), add(y, x);
}
dfs(1);
printf("%d", ans);
return 0;
}
debug:
while (-- n)
{
scanf("%d%d", &x, &y);
add(x, y), add(y, x);
}
- main函数中循环若写成以上形式,那么每次循环都将修改n的值。而dfs需要
m_s = max(m_s, n - sum,很显然,这个操作中的n就是指树中节点的数量,不能修改。所以应该用临时遍历代替n进行循环 - main函数中,若写
dfs(0),那么答案是错误的,dfs的参数可以写1n中的任意数字。为什么?因为dfs将先通过h数组索引单链表头节点,h数组以编号1n作为索引,这在add函数中就能体现
847. 图中点的层次
847. 图中点的层次 - AcWing题库
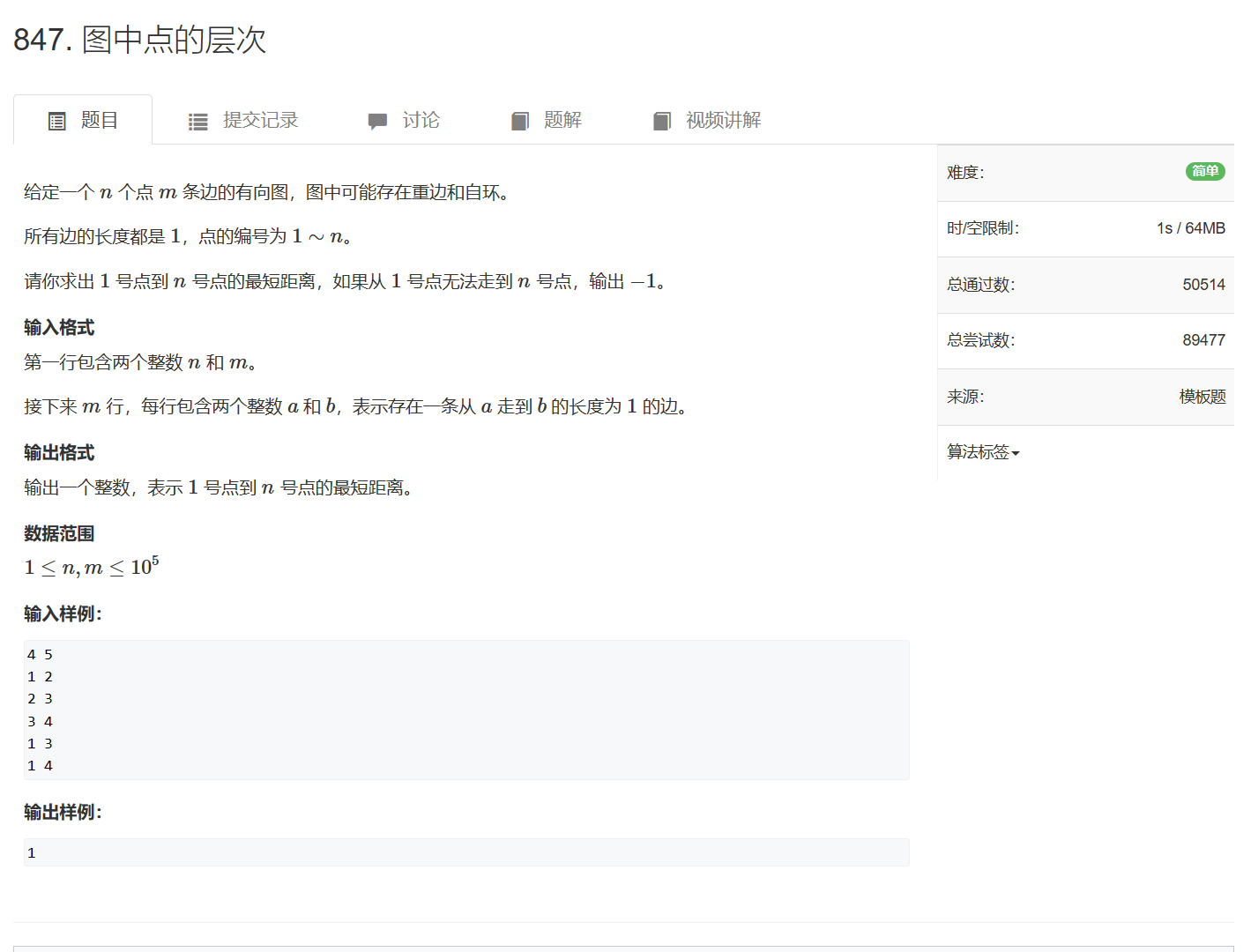
还是广搜,从1号点开始搜索,维护一个距离数组d表示其他点与1号点的距离
初始化距离数组为-1,最后返回d[n]
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int d[N], q[N];
int n, m, x, y;
int h[N], e[N], ne[N], idx = 1;
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
void bfs()
{
memset(d, -1, sizeof(d));
int hh = 0, tt = -1;
q[++ tt] = 1, d[1] = 0;
while (hh <= tt)
{
int u = q[hh ++ ];
for (int i = h[u]; i != -1; i = ne[i])
{
int t = e[i];
if (d[t] == -1) d[t] = d[u] + 1, q[++ tt] = t;
}
}
}
int main()
{
memset(h, -1, sizeof(h));
scanf("%d%d", &n, &m);
while (m -- )
{
scanf("%d%d", &x, &y);
add(x, y);
}
bfs();
printf("%d\n", d[n]);
return 0;
}
debug:看了半天,结果是main函数没有调用bfs,乐
拓扑序练习题
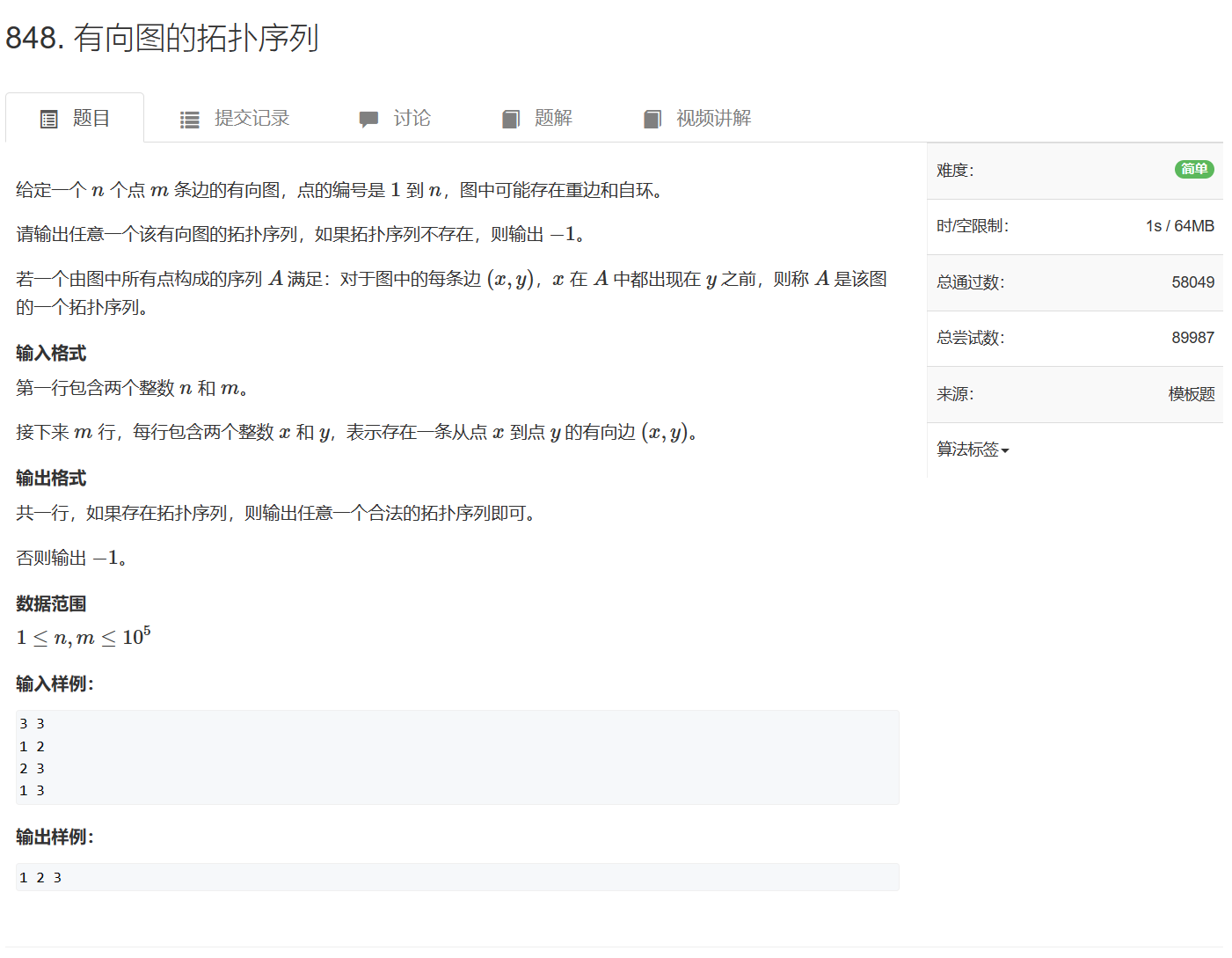
848. 有向图的拓扑序列
848. 有向图的拓扑序列 - AcWing题库
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1e5 + 10;
int e[N], ne[N], h[N], idx = 1;
int d[N], q[N];
int n, m, x, y;
void add(int x, int y)
{
e[idx] = y, ne[idx] = h[x], h[x] = idx ++ ;
}
bool topsort()
{
int hh = 0, tt = -1;
for (int i = 1; i <= n; ++ i )
{
if (!d[i]) q[++ tt ] = i;
}
while (hh <= tt)
{
int u = q[hh ++];
for (int i = h[u]; i != -1; i = ne[i])
{
int t = e[i];
if (--d[t] == 0) q[++ tt ] = t;
}
}
return tt == n - 1;
}
int main()
{
memset(h, -1, sizeof(h));
scanf("%d%d", &n, &m);
while (m -- )
{
scanf("%d%d", &x, &y);
add(x, y);
d[y] ++ ;
}
if (topsort()) for (int i = 0; i < n; ++ i ) printf("%d ", q[i]);
else printf("-1\n");
return 0;
}

